W świecie cyberbezpieczeństwa i analizy OSINT bardzo łatwo ulec fascynacji zaawansowanymi podatnościami typu zero-day, spektakularnymi exploitami czy masowymi wyciekami danych. Rzeczywistość bywa jednak znacznie bardziej przyziemna. Najbardziej dewastujące ataki to te, które łączą proste złośliwe oprogramowanie z precyzyjną socjotechniką — jak choćby powszechna dziś oszustwo na blika.
Niedawno uczestniczyłem w toczącej się w czasie rzeczywistym walce o uratowanie konta na Facebooka znajomej. To kosztowne, lecz doskonałe studium przypadku — pokazuje nie tylko, jak dziś wygląda cyfrowa walka wręcz, ale przede wszystkim, jak napastnicy potrafią obrócić mechanizmy bezpieczeństwa aplikacji przeciwko samej ofierze.
Jak wygląda metoda na blika?
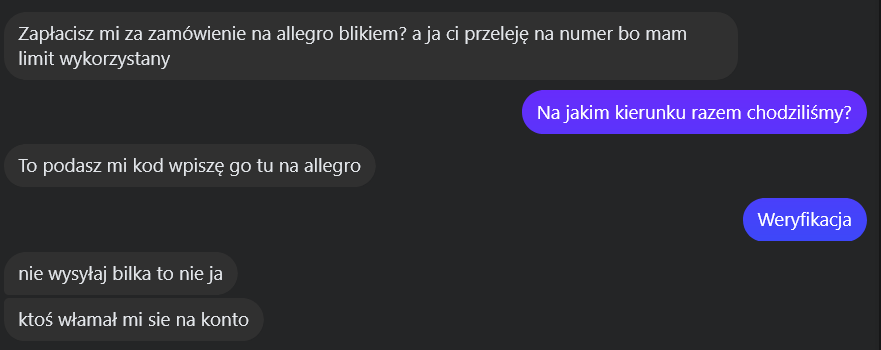
Pewnego dnia dostałem na Messengerze wiadomość od znajomej z prośbą o przelew BLIK-iem na poczet zamówienia na Allegro. Gdy zacząłem weryfikować rozmówcę pytaniem o szczegół znany tylko nam obojgu, w tym samym oknie pojawiły się kolejne wiadomości. Tym razem właścicielka konta napisała: „nie wysyłaj blika to nie ja, ktoś włamał mi się na konto”. Oszust i ofiara pisali do mnie niemal równocześnie. Od tej chwili miałem kilkanaście minut, żeby pomóc jej odzyskać konto.
Rozłóżmy ten wektor ataku na czynniki pierwsze.
Punkt wyjścia: Przejęcie poczty i wielki mit 2FA
Wiele osób żyje w przekonaniu, że dwuskładnikowe uwierzytelnianie (2FA) chroni przed każdym rodzajem włamania. Ten przypadek brutalnie to weryfikuje. Aby zrozumieć, jak doszło do włamania, trzeba rozgraniczyć dwa mechanizmy, które napastnicy wykorzystali sekwencyjnie.
Wszystko zaczęło się od infekcji złośliwym oprogramowaniem typu infostealer — prawdopodobnie dostarczonego przez phishing lub złośliwą stronę — z rodziny RedLine lub Lumma. Tego rodzaju malware wyciąga z profilu przeglądarki loginy, hasła oraz aktywne pliki cookie sesji.
Krok 1: Kompromitacja powiązanej skrzynki e-mail (autoryzacja OTP)
Kluczowym dowodem analitycznym była informacja od znajomej: „znalazłam na mailu kody do logowania sprzed dwóch dni, a ja nie wchodziłam na FB od miesiąca”. Wyklucza to scenariusz, w którym pierwsze logowanie nastąpiło wyłącznie za pomocą sklonowanego ciasteczka sesyjnego.
Scenariusz przebiegł następująco:
- Napastnicy użyli skradzionego hasła, by zalogować się na Facebooka z nowego urządzenia.
- System Meta wymusił weryfikację kodem jednorazowym (OTP) wysłanym na skrzynkę e-mail.
- Ponieważ hasło do poczty było identyczne lub również zapisane w przeglądarce, hakerzy weszli na skrzynkę, odczytali kod OTP i zautoryzowali logowanie.
- Natychmiast przenieśli wiadomości od Meta do kosza, by ofiara nie zorientowała się w sytuacji.
Krok 2: Kradzież sesji (Session Hijacking) w celu utrzymania dostępu
Po poprawnym wpisaniu kodu OTP napastnicy wygenerowali i przechwycili nowe, unikalne tokeny sesyjne (pliki cookie). Od tego momentu nie potrzebowali już dostępu do skrzynki e-mail ani wpisywania haseł. Operowali na sklonowanym tokenie sesyjnym, co pozwoliło im na rozsyłanie spamu i dynamiczne blokowanie działań obronnych ofiary.
Bezpieczna pamięć jako narzędzie izolacji
Gdy sprawcy zaczęli masowo rozsyłać znajomym prośby o płatność BLIK pod pretekstem pilnego opłacenia zamówienia na Allegro, jedna z osób dała się zmanipulować i straciła 1000 zł. Gdy właścicielka konta zorientowała się w sytuacji, zalogowała się i wysłała ostrzeżenie: „nie wysyłaj blika to nie ja, ktoś włamał mi się na konto”.
W tym momencie rozpoczęła się właściwa bitwa. Napastnicy, widząc aktywność prawowitej właścicielki, postanowili odciąć ją od informacji. Wykorzystali do tego funkcję Bezpiecznej pamięci (Secure Storage) — warstwę zarządzania kluczami wbudowaną w szyfrowanie end-to-end (E2EE) na Messengerze.
Ważna uwaga techniczna: To nie był żaden atak na kryptografię E2EE ani jej złamanie. Było to cyniczne nadużycie funkcji bezpieczeństwa. Napastnicy, mając uprawnienia administratora konta, skonfigurowali własny kod PIN do Bezpiecznej pamięci — warstwy leżącej nad szyfrowaniem E2EE, nie w samym szyfrowaniu.
W efekcie cała historia konwersacji prowadzonych przez oszustów stała się dla znajomej całkowicie niedostępna. Czaty były zaszyfrowane kluczem, który znali wyłącznie hakerzy. Cel był prosty: uniemożliwić ofierze identyfikację osób, do których właśnie wysłano prośby o BLIK-a, i maksymalnie opóźnić jej reakcję obronną.
Cyfrowa walka wręcz — zarządzanie sesją na żywo
Najbardziej emocjonujący moment incydentu to bezpośrednie starcie o kontrolę nad panelem logowania. Przestępcy próbowali bez przerwy wylogowywać znajomą z jej własnego konta.
Dzięki temu, że byłem z nią w stałym kontakcie na innym kanale, mogłem instruować ją na bieżąco. Sama zmiana hasła podczas trwającej sesji napastników to za mało — gdyby hakerzy byli szybsi, mogliby zmienić powiązany numer telefonu lub e-mail i bezpowrotnie przejąć konto.
Zastosowaliśmy jedyną skuteczną taktykę: sekwencyjne, agresywne wyrzucanie urządzeń intruzów w zakładce bezpieczeństwa Meta przy jednoczesnym zatwierdzaniu nowych poświadczeń logowania. Każda sekunda miała znaczenie.
Wskazówka OSINT: geolokalizacja to nie tożsamość
Wyświetlana w panelu geolokalizacja (system Windows logujący się z Wrocławia) nie identyfikuje bezpośrednio sprawcy. Wskazuje jedynie przybliżony punkt dostępu lub infrastrukturę pośredniczącą — w tym przypadku najpewniej węzeł wyjściowy sieci VPN lub serwer proxy. Warto o tym pamiętać: nawet prawdziwy adres IP daje precyzję na poziomie miasta, a nie osoby — samodzielne „namierzanie” sprawców na tej podstawie jest bezcelowe i może być niebezpieczne.
Kupowanie czasu — waste of attacker’s time
Zanim hakerzy zorientowali się, że pomagam znajomej, i zablokowali mój profil ze skradzionego konta, postanowiłem zastosować technikę scambaitingu. Podawałem fałszywe kody BLIK (z celowo zmienioną jedną cyfrą) i symulowałem problemy techniczne.
Z analitycznego punktu widzenia to prosta matematyka: zmuszenie operatora oszustwa do analizowania błędnych danych wejściowych i generowania odpowiedzi kupuje cenny czas. Wywalczone kilkanaście minut pozwoliło znajomej przeprowadzić procedurę zmiany haseł i powiadomić kontakty z listy.
Ważne zastrzeżenie: Tego rodzaju interakcja z napastnikiem to nie jest zabawa dla każdego. Co więcej, angażowanie się w rozmowę z atakującym może wydłużyć atak w innych wektorach lub ujawnić dodatkowe informacje o ofierze. Dla większości użytkowników bezwzględnie zalecaną procedurą jest natychmiastowe zerwanie kontaktu, zabezpieczenie własnych pieniędzy i szybkie ostrzeżenie otoczenia innymi kanałami.
Szybka ściągawka: Co robić po przejęciu konta?
Zasada nadrzędna: Jeżeli podejrzewasz infekcję komputera, wszelkie działania ratunkowe wykonuj wyłącznie z innego, zaufanego urządzenia (np. smartfona). W przeciwnym razie nowo wpisane hasła ponownie mogą trafić do hakerów.
- Zmień hasło główne i e-mail. Zmień hasło do profilu społecznościowego oraz powiązanej skrzynki e-mail — zanim zrobisz cokolwiek innego.
- Wyloguj wszystko i wszędzie. Dopiero po zmianie haseł wybierz opcję „Wyloguj ze wszystkich urządzeń”. Unieważnia to aktywne sesje ze skradzionymi tokenami — a napastnicy nie mogą już zalogować się ponownie, bo hasło jest już inne.
- Przejrzyj filtry na poczcie. Sprawdź reguły i przekierowania w skrzynce e-mail. Hakerzy często ustawiają filtry automatycznie usuwające powiadomienia od Meta/Facebooka.
- Włącz silne 2FA. Przejdź na weryfikację opartą o zewnętrzną aplikację autoryzującą (np. Proton Pass, Google Authenticator), rezygnując z kodów SMS lub e-mail.
- Przeskanuj sprzęt. Przeskanuj komputer programem antywirusowym z aktualnymi sygnaturami (np. Malwarebytes, ESET) lub przeinstaluj system.
- Migruj do menedżera haseł. Przenieś wszystkie hasła z przeglądarki do dedykowanego menedżera (np. Proton Pass, Bitwarden). Przeglądarka to nie sejf.
- Ustaw własny PIN do Bezpiecznej pamięci (Secure Storage). W ustawieniach Messengera skonfiguruj własny kod PIN zanim zrobi to ktoś inny. PIN jest opcjonalny, ale jego brak oznacza, że napastnik z dostępem do Twojej sesji może ustawić go przed Tobą – i trwale odciąć Cię od historii czatów.
Najważniejsza lekcja
Weryfikacja dwuskładnikowa (2FA) skutecznie chroni przed kradzieżą samego hasła. Niestety, w żaden sposób nie uchroni Cię przed kradzieżą aktywnej sesji (ciasteczek) lub przejęciem skrzynki e-mail z zainfekowanego urządzenia.
Współczesne kradzieże tożsamości cyfrowej to nie filmowe „hakowanie” kodu w zielonej konsoli. To sprawnie zarządzane operacje, które bezlitośnie wykorzystują nieuwagę i błędy w podstawowej higienie cyfrowej. Dbajcie o swoje sesje i nie zapisujcie haseł w przeglądarkach.
Co z odzyskaniem pieniędzy?
Znajoma zgłosiła sprawę na policję — przede wszystkim w imieniu koleżanki straciła 1000 zł. Odpowiedź była szczera: zgłoszenie zostanie przyjęte, ale szanse na namierzenie sprawców i odzyskanie pieniędzy są niewielkie. Tego rodzaju operacje prowadzone są przez VPN i proxy, a ślad cyfrowy celowo zacierany na każdym etapie. Policja przyjmuje zgłoszenia, ale bez międzynarodowej współpracy operacyjnej i szczęścia rzadko kończy się to wyrokiem.
To pokazuje, że oszustwo na blika jest w 2026 bardzo skuteczne, a szansę na wykrycie bardzo niewielkie.